Three categories I keep reaching for lately 🚀
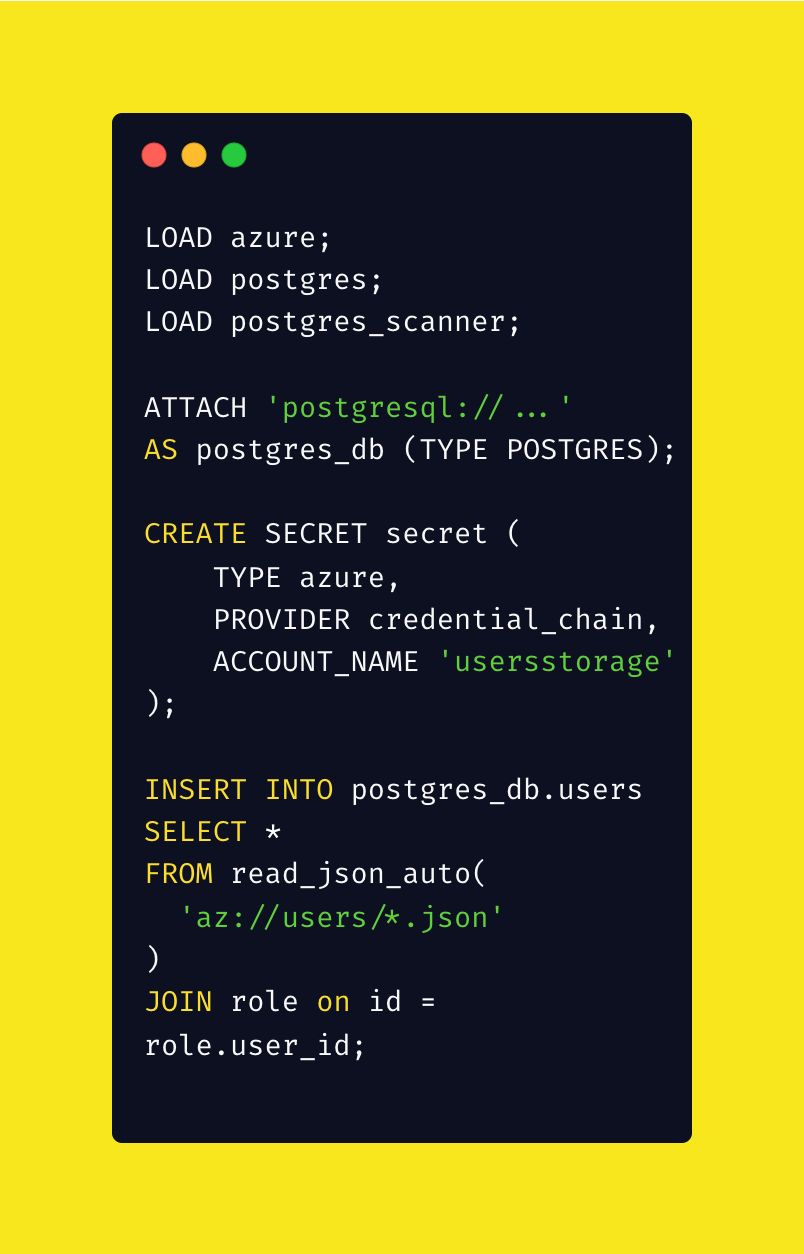
Azure / AWS ☁️
- Connect straight to S3 or Azure Storage and query files directly
- Use secure, modern auth like RBAC, tokens and CLI creds
JSON / CSV 📄
- Load and explore semi-structured or flat files from anywhere
- Automatic schema inference that feels like magic
- Use asterisk wildcard to easily load multiple files
Postgres / MySQL 🗄️
- Attach external databases as if they were part of DuckDB
- Join and query across multiple systems without friction
- Stream data both ways for fast ETL and rapid prototyping
Still not on the “ducktrain”? Have a look at duckdb.org.
Originally posted on LinkedIn.